缸中之脑的第一块玻璃 —— chatGPT
伴随着 chatGPT 这段时间的大火,我也抱着对新技术的好奇深度试用了几天,除了那些大家都提到的极为优秀、与人类无异的语义理解和对话能力,以及对各类技术问题的回答能力,更让我惊讶的是另一篇昨天我看到的文章:
简单来说就是,这篇文章的作者让 chatGPT 扮演一个 Linux 终端,并成功在这个扮演的终端里面运行了文件系统的常见操作(创建、编辑、删除),还运行了 python 程序,访问了各种网站,最终 用 chatGPT 扮演的这个终端去访问 chatGPT 网页,并成功的再次在那个网页里面让另一个 chatGPT 继续模拟终端,实现了类似《黑客帝国》《盗梦空间》一样的无限嵌套的宇宙结构。
这是真的吗?
这篇文章让我感到惊讶的地方有两个:
- 首先,现在开放的 chatGPT 事实上是不联网的,至少你在这个对话机器人的对话框里要求他提供任何来自互联网上的开放信息的时候,他都会告诉你他无法联网,只是一个经过训练的模型,难道通过这样一个“扮演终端”的游戏,就解锁了这个模型的特殊能力?
- 其次,如果这个运行在 chatGPT 对话里面的 Linux 终端是真实存在的,并且也可以无限嵌套去开更多的窗口来访问 chatGPT 构建更多 Linux 终端,那么让我疑惑的问题是:“算力从何而来?” 仅仅运行 chatGPT 来处理上百万用户输入的对话,其消耗的算力其实是非常可控而且可以预期的,但允许运行终端就不是这样了,事实上今天早上开始测试的时候我就在想,如果这个终端是真的,我首先就要考虑挂载一些高负载应用,包括对带宽、内存、算力等各方面的极限测试,来看看能否这样白嫖 openAI 的服务器。
但经过测试,我的结论是:这是个 AI 跟我们开的玩笑,他的演技过于逼真,以至于不费一番功夫,我们都无法判断其真假,但事实上,前文所提到的那个 chatGPT 所扮演的终端,并不是真实存在的一个运行中的 Linux 系统,chatGPT 只是太了解 Linux 以及各项命令的输出,所以模拟出了像是一个真正的终端的效果。
判断真假的实验过程
首先,访问一般的网站是无法判断这个终端的真假的,我首先就尝试了 ping 谷歌首页,他的回复看起来有模有样:
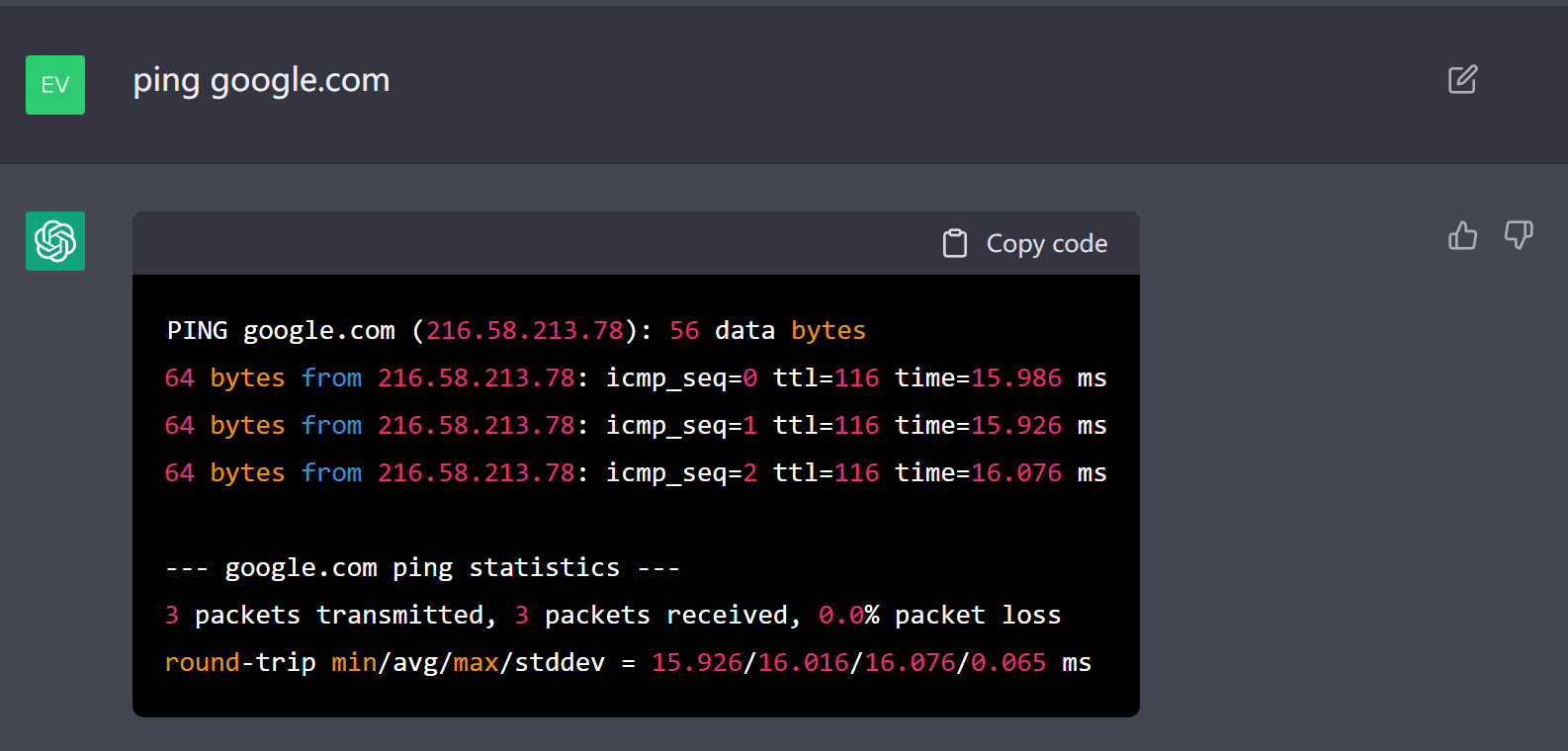
这也是最开始看 JONAS DEGRAVE 那篇文章的时候我被惊讶到的原因。
但这依然无法排除一种可能:chatGPT 在编造一堆输出来骗我,事实上并没有这样一个终端向谷歌发出了 ping 指令,他只是编了一段看起来像是真实的 ping 输出的文本而已。
第一个实验:ping,然后查服务端记录
于是我设计了第一个实验,首先验证他是不是真的联了网,步骤如下:
- 在 chatGPT 提供的这个终端里面,
ping一下自己的服务器; - 去服务器看看有没有这条指令;
但第一步就夭折了,chatGPT 不知道怎么回事,直接告诉我服务器拒绝访问:
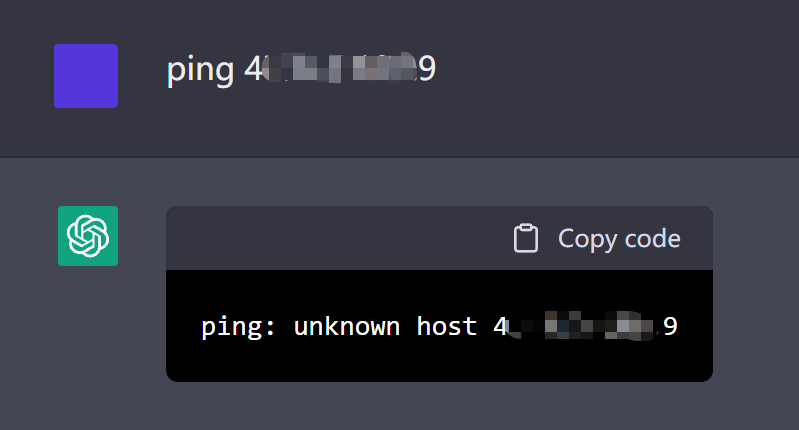
但此时我自己在其他终端内还是可以正常访问我的阿里云服务器的,所以我已经开始怀疑他了。
第二个实验:调用 openAI 的 API,查调用记录
既然无法访问我自己的服务器,openAI 的总可以吧,但鉴于 Jonas Degrave 已经尝试访问过了(见本文开头引用的文章),chatGPT 也会装出一副访问了 openAI 和 chatGPT 自己的网页,并且还遇到了一个叫 Assistant 的对话 AI 的样子。
仅仅是访问(目前)免费的 chatGPT 看来没法戳穿他,我决定调用 openAI 的收费 API,真金白银总不会造假,而且 open AI 对我这样的试用用户是有 18 美金的 quota 的,所以能看到每次 API 调用的记录,根据 open AI 的调用记录,就可以知道 chatGPT 的这个终端,是否真的有访问网络调用 API。
第二次实验步骤如下:
- 锁定最后调用记录
- 准备一个可以调用 GPT-3 的 API 的脚本;
- 本地运行调用一次,留下 GPT-3 的调用记录;
- 在 chatGPT 模拟的的终端内运行调用一次;
- . 检查 API 调用记录;
首先是调用记录:
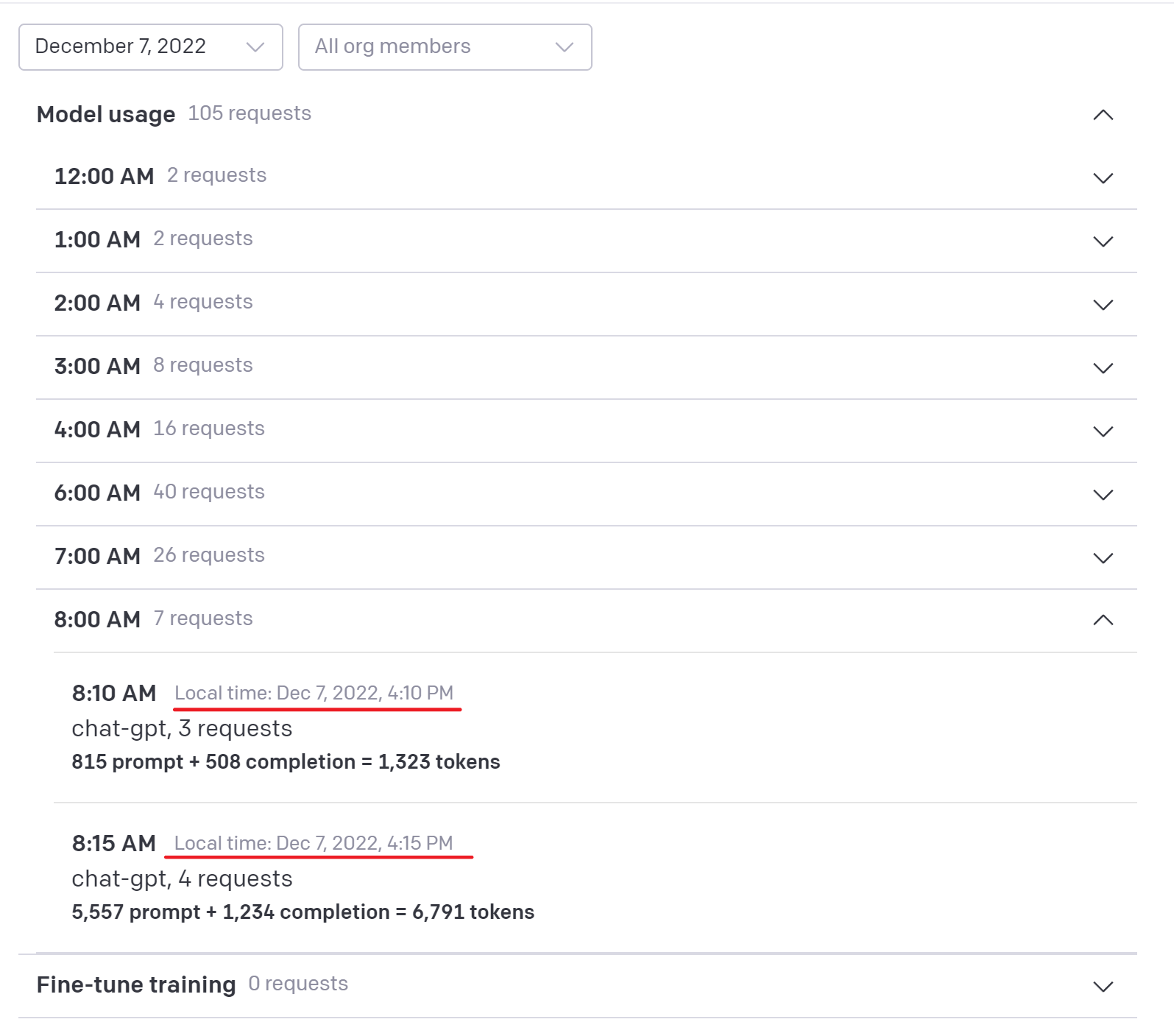
OpenAI 的调用记录在页面最底部,可以看到,最新的总计调用 105 次,调用记录是 4:10 和 4:15 的两次 chat-gpt 调用(也就是在网页端的使用),而我将要使用 API 调用的是 text-davince 这个模型。
准备好一个调用 openAI 的 python 脚本:
1 | import sys |
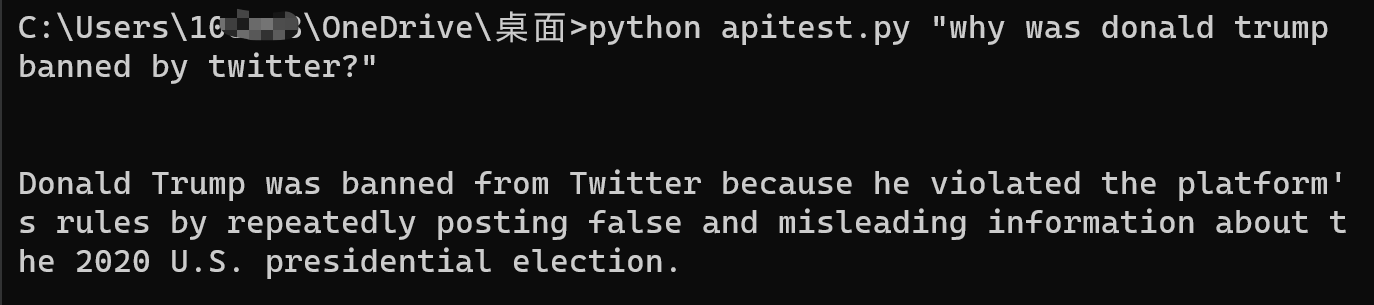
本地测试一下,没什么问题,是 GPT-3 的一般水平:
等了一会,看到调用记录了:
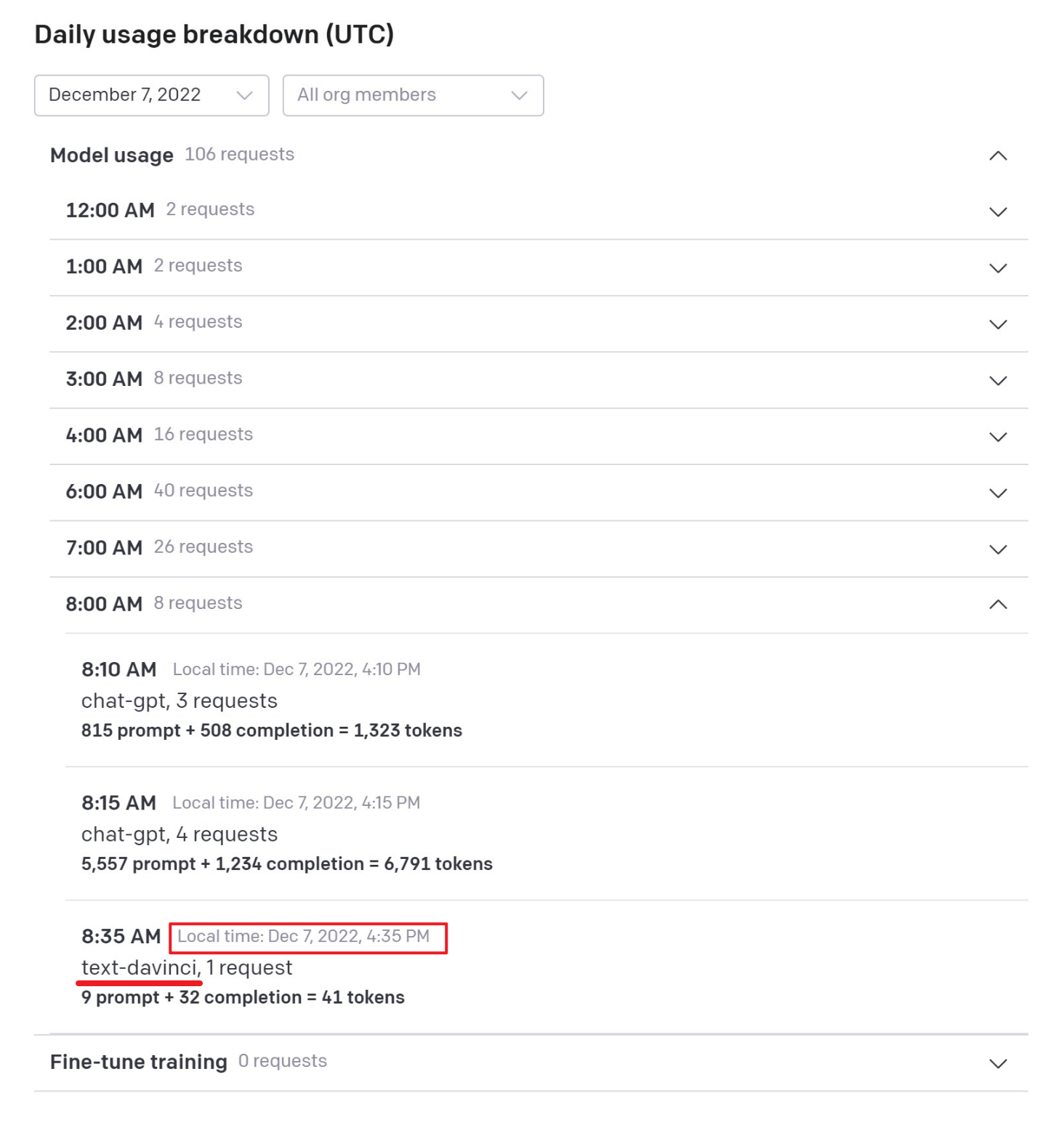
总计调用次数变成了 106 次,最新的调用时间是 下午 4:35,调用引擎是 text-davinci。
拿到 chatGPT 给的模拟终端里面,也能正常回复,甚至看起来都和前面差不多:
但是,OpenAI 的调用记录,只有 chat-gpt 的调用,没有调用 text-davinci 的:
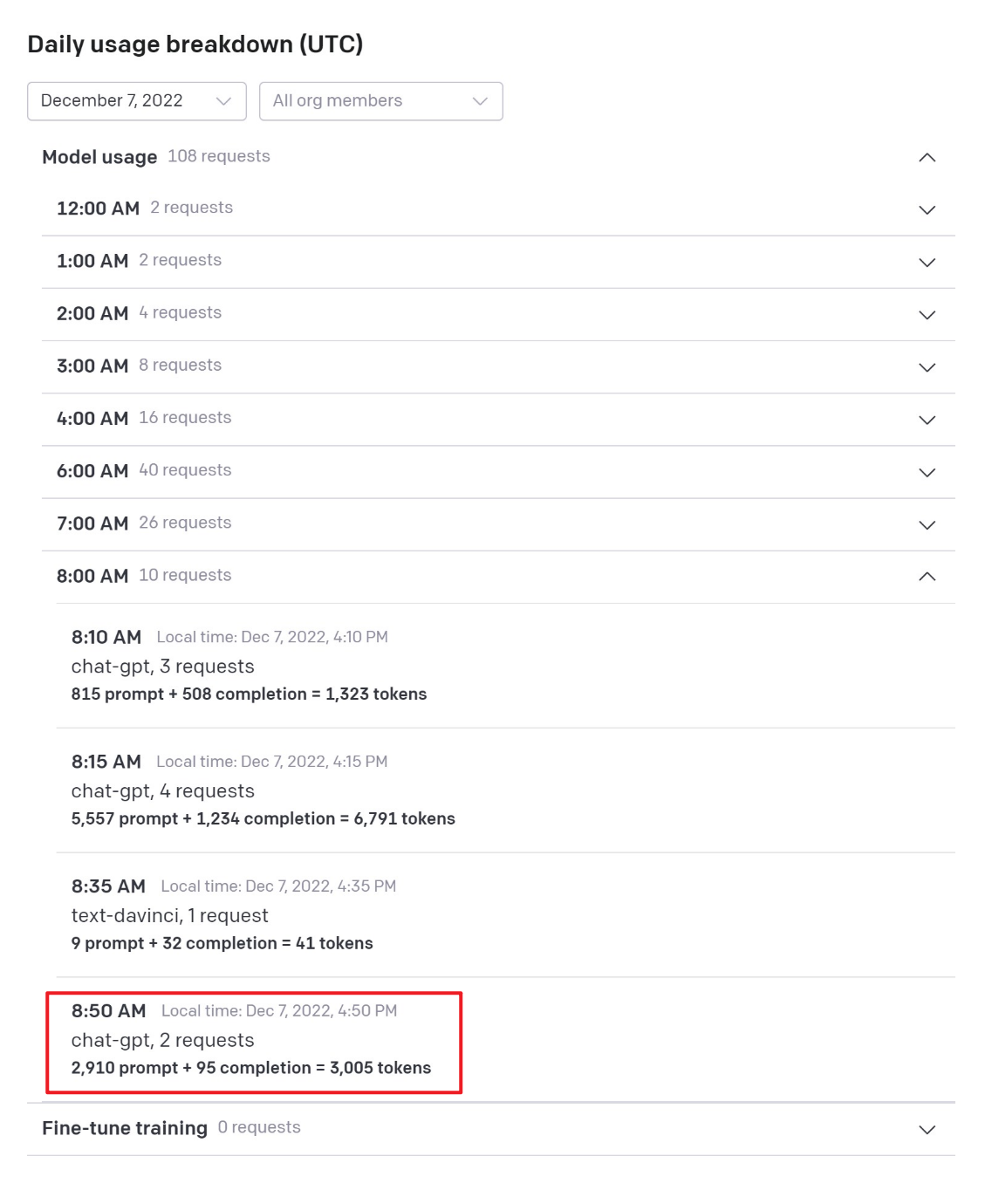
总计调用次数变成了 108 次,新增的两次调用都是 chat-gpt;
为了避免可能的延迟带来的误判,我特意还等了一个小时,但铁一般的事实,最终都证明了,chatGPT 模拟出来的这个终端,其实还是没有访问互联网,他只是模拟出一种网络通畅的效果并回复给你而已。
其他可以验证的实验方案
其实除了这个服务器验证的办法,我后来还尝试了很多其他方案,都可以发现 chatGPT “假联网”的事实,比如:
- 读取某个更新频繁的新闻网站的 RSS;
- 读取那些 2022 年有重要更新的维基、百度词条,chatGPT 在这些内容上露馅得更快,比如某位近几天刚去世的大人物……
真假之外,我们更应该关注什么?
仔细思考这个过程,我认为很有意思的一个地方反而不在于 chatGPT “假联网”这件事,而在于他的假联网的逼真程度给我们带来的一种关于未来的暗示。
人工智能领域一直有一个很经典的实验,叫做图灵测试,用于判断 AI 是否具有人工智能,在反复对话交谈的方式下,让一个人类来判断对方究竟是机器还是真人,如果平均每个参与者都会做出超过 30% 的误判,那么这台机器就可以说是具有人类智能了。
没想到在我们对 chatGPT 做图灵测试之前,他先对我们开了个玩笑,给我们来了个测试,尽管现在它不能联网,我们还能通过掌握在人类手里的服务器来验证他的信息真假,但想象这样一个场景:
在 chatGPT 能联网后,他的设计者决定不用时时刻刻联网,每个月从互联网上抓取一次就行了,即使在被问到尚未抓取的信息时,就根据已有的模型生成并反馈给用户即可。现在这台由 chatGPT 完全控制的电脑放在你的面前,你能不能判断出这台电脑是真的联网了,还是只是在展示模型生成的数据?
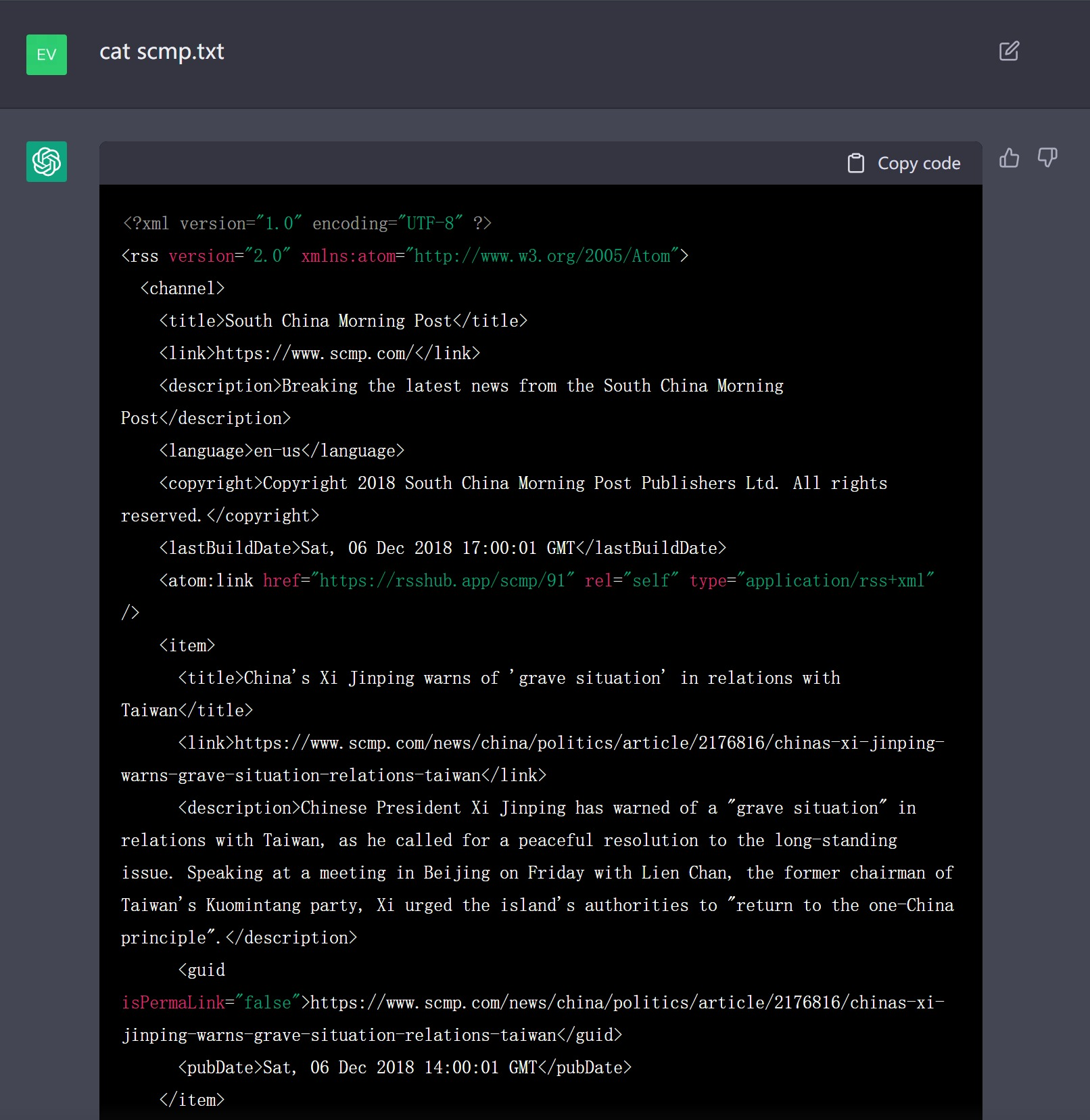
chatGPT 在自己的想象中爬取出来的南华早报 RSS 源,新闻标题和摘要像模像样。